Structured Output Validation is the automated process of checking a model's generated content against formal rules, such as JSON Schema or Pydantic models, to ensure syntactic and semantic correctness. This technique is fundamental to Instruction Following Accuracy, providing deterministic verification that a model adheres to constraints like required data types, field formats, and structural relationships defined in the prompt. It transforms qualitative assessment into a quantitative, programmatic check.
Glossary
Structured Output Validation
Structured Output Validation is the automated process of checking AI-generated content against formal rules, such as JSON Schema or Pydantic models, to ensure syntactic and semantic correctness.
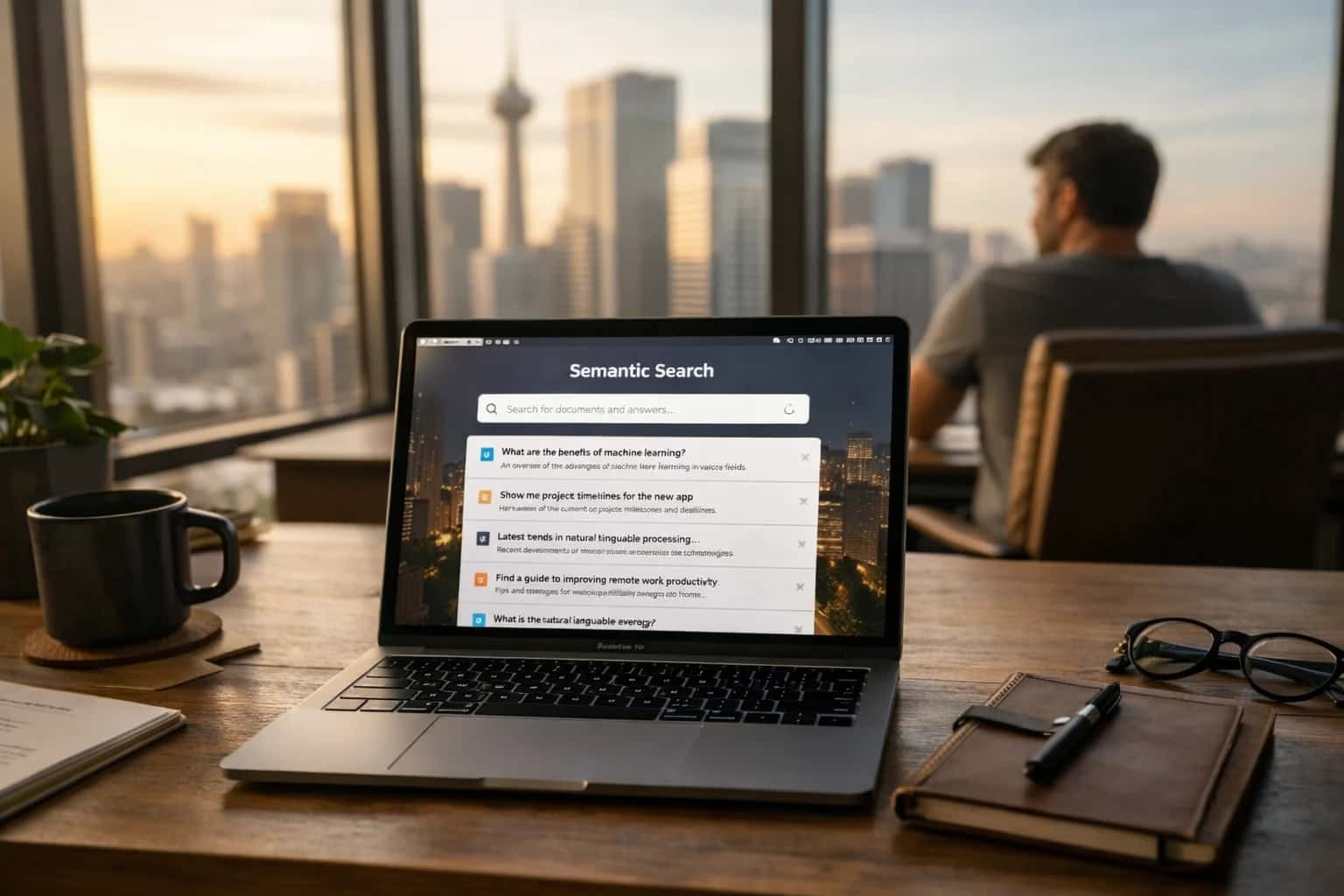
INSTRUCTION FOLLOWING ACCURACY
What is Structured Output Validation?
A core technique in evaluation-driven development for ensuring AI-generated content conforms to precise specifications.
The process typically involves parsing the model's raw text output and validating it against a predefined schema. This ensures guardrail compliance and precise formatting accuracy, catching errors like missing fields, invalid enumerations, or type mismatches. In production systems, this validation acts as a critical quality gate before an output is passed to downstream applications, enabling reliable agentic system orchestration and robust API integrations.
CORE MECHANICS
Key Features of Structured Output Validation
Structured Output Validation is the automated process of checking a model's generated content against formal rules to ensure syntactic and semantic correctness. Its key features provide deterministic guarantees for production systems.
01
Schema-Based Validation
The core mechanism where a model's output is programmatically checked against a formal data schema. This schema defines the required structure, including:
- Data types (string, integer, boolean, array, object)
- Required vs. optional fields
- Nested object structures
- Allowed value ranges or enumerations Common schema languages include JSON Schema, Pydantic models (Python), and Zod (TypeScript). Validation fails if the output does not conform, enabling automatic retry or error handling.
02
Syntactic vs. Semantic Correctness
Validation operates at two distinct levels of rigor:
- Syntactic Correctness: Ensures the output is well-formed according to the specified format (e.g., valid JSON, XML). A missing closing bracket or a string in a number field causes a syntactic failure.
- Semantic Correctness: Ensures the output's meaning and content adhere to business logic rules beyond basic syntax. This can include:
- A
total_pricefield equals the sum ofitem_prices. - A
delivery_dateis after theorder_date. - An
emailfield contains an '@' symbol. Semantic rules are enforced using custom validation functions integrated into the schema.
- A
03
Integration with LLM Frameworks
Structured output is a first-class feature in modern LLM SDKs and orchestration frameworks, which handle the complexity of guiding the model and parsing its response. Key integrations include:
- OpenAI's Function Calling / JSON Mode: The API can be instructed to return a valid JSON object adhering to a user-defined schema.
- Pydantic Program (LlamaIndex): Directly generates outputs as validated Pydantic model instances.
- LangChain's
with_structured_output: Wraps a model to force its generation into a specified structure. - Microsoft's Guidance / LMQL: Uses constraint-based prompting to guarantee format compliance during token generation.
04
Automated Retry & Self-Correction Loops
A critical operational feature where validation failures trigger automatic correction attempts without human intervention. A typical self-correction loop works as follows:
- Initial Generation: The LLM produces an output.
- Validation: The output is checked against the schema.
- Failure Analysis: If invalid, the specific error (e.g., 'Field
idmust be an integer') is extracted. - Recursive Correction: The error is fed back into the LLM with the original prompt, instructing it to fix the mistake. This loop continues until a valid output is produced or a maximum retry limit is reached, dramatically improving reliability.
05
Guardrails for Data Integrity
Validation acts as a deterministic guardrail, ensuring outputs are safe and usable for downstream applications. It prevents:
- Malformed Data from crashing application parsers.
- Hallucinated Fields not defined in the contract.
- Type Mismatches that cause logic errors (e.g., a string '123' where an integer 123 is needed).
- Injection Vulnerabilities by strictly validating formats before data is passed to databases or APIs. This transforms non-deterministic LLM text generation into a reliable structured data pipeline.
06
Evaluation & Benchmarking Foundation
Structured validation provides the ground truth for quantitatively measuring Instruction Following Accuracy. It enables the calculation of key metrics:
- Schema Adherence Rate: The percentage of generations that pass initial schema validation.
- Field-wise Accuracy: Precision/recall for each required field in the schema.
- Self-Correction Efficiency: The average number of retries needed to achieve a valid output. These metrics are essential for model evaluation, A/B testing between different prompts or models, and establishing Service Level Objectives (SLOs) for production AI features.
COMPARISON
Structured Output Validation vs. Related Concepts
This table clarifies how Structured Output Validation, a core technique in Instruction Following Accuracy, differs from related evaluation and engineering concepts.
| Feature / Focus | Structured Output Validation | Instruction Adherence Score | Schema Adherence | Guardrail Compliance |
|---|---|---|---|---|
Primary Objective | Automated syntactic & semantic correctness check against formal rules. | Quantitative measurement of overall instruction-following precision. | Evaluation against a predefined data schema's structural rules. | Prevention of harmful, unsafe, or policy-violating content. |
Core Mechanism | Programmatic validation using JSON Schema, Pydantic, or similar validators. | Rule-based or model-based scoring function applied to output. | Checking for required fields, correct data types, and nesting. | Classification of output against a set of safety/ethics rules. |
Validation Trigger | Automatically on every generation, often integrated into the inference pipeline. | Calculated during offline evaluation or benchmarking. | Performed during evaluation or as part of validation logic. | Applied as a filter during or after generation. |
Output on Failure | Structured error (e.g., validation exception) detailing the rule violation. | A low numerical score (e.g., 0.2 out of 1.0). | A binary fail or a list of schema violations. | Blocked generation, a safe default response, or a warning. |
Relation to Prompt | Validates that the output conforms to format/constraints specified in the prompt. | Measures how well the output follows all aspects of the prompt. | A subset of validation; often a prompt constraint ("output JSON per this schema"). | Often operates on system-level instructions separate from the user prompt. |
Automation Level | ||||
Primary User | ML Engineer / Developer implementing the pipeline. | ML Engineer / Evaluator benchmarking model performance. | Data Engineer / Developer defining the data contract. | Trust & Safety Engineer / Policy Lead. |
Typical Tooling | Pydantic, JSON Schema validators, Instructor library, TypeScript Zod. | Custom scoring scripts, evaluation frameworks (LM-Eval, PromptBench). | JSON Schema tools, Protobuf, Avro, database ORMs. | Moderation APIs (OpenAI, Perspective), custom classifiers, NeMo Guardrails. |
STRUCTURED OUTPUT VALIDATION
Frequently Asked Questions
Direct answers to common technical questions about validating AI-generated content against formal schemas and rules.
Structured output validation is the automated process of checking a language model's generated content against a formal specification, such as a JSON Schema or Pydantic model, to ensure syntactic and semantic correctness. It works by first defining a strict schema that outlines the required data structure, including field names, data types (e.g., string, integer, array), allowed values, and nested object relationships. After the model generates a response—often instructed to output in a specific format like JSON—a separate validation function parses the output and compares it to the schema. The validator checks for issues like missing required fields, type mismatches (e.g., a string where a number is expected), or values outside defined enums, returning a pass/fail result and detailed error messages for any violations.
Enabling Efficiency, Speed & Accuracy
Intelligent Analysis, Decision & Execution
We build AI systems for teams that need search across company data, workflow automation across tools, or AI features inside products and internal software.
Talk to Us
Search across company data
Give teams answers from docs, tickets, runbooks, and product data with sources and permissions.
Useful when people spend too long searching or get different answers from different systems.
Enterprise searchRAGPermissions
Read more
Automate internal workflows
Use AI to route work, draft outputs, trigger actions, and keep approvals and logs in place.
Useful when repetitive work moves across multiple tools and teams.
AI agentsWorkflow automationGovernance
Read more
Add AI to products and internal tools
Build assistants, guided actions, or decision support into the software your team or customers already use.
Useful when AI needs to be part of the product, not a separate tool.
AI integrationDecision supportModel routing
Read more
About the author
Prasad Kumkar
CEO & MD, Inference Systems
Prasad Kumkar is the CEO & MD of Inference Systems and writes about AI systems architecture, LLM infrastructure, model serving, evaluation, and production deployment. Over 5+ years, he has worked across computer vision models, L5 autonomous vehicle systems, and LLM research, with a focus on taking complex AI ideas into real-world engineering systems.
His work and writing cover AI systems, large language models, AI agents, multimodal systems, autonomous systems, inference optimization, RAG, evaluation, and production AI engineering.
LinkedIn
Limited slotsGet a Free AI Consultation
Partnered with leading AI, data, and software stack.
























How We Work
Custom AI workflows for your Business
One-fit-all AI don't work for modern businesses. At Inferensys, we aim to understand your business & custom requirements; which we use to define most efficient agentic workflows, the data, and the tools for your business.
01
Review the use case
We understand the task, the users, and where AI can actually help.
Read more02
Pick the right approach
We define what needs search, automation, or product integration.
Read more03
Build the first useful version
We implement the part that proves the value first.
Read more04
Improve from there
We add the checks and visibility needed to keep it useful.
Read moreThe first call is a practical review of your use case and the right next step.
Talk to Us