A logical data fabric is a data management architecture that provides a virtualized, integrated view of data across sources without physically moving or replicating it, using semantic models and query federation. It acts as an abstraction layer, connecting to underlying databases, data lakes, and APIs through mapping definitions (like R2RML or RML) to present a unified logical model, often as a virtual knowledge graph. This enables real-time, governed access to distributed data while preserving source autonomy and reducing data duplication.
Glossary
Logical Data Fabric
A logical data fabric is a data management architecture that provides a virtualized, integrated view of data across sources without physically moving or replicating it, using semantic models and query federation.
SEMANTIC DATA FABRIC
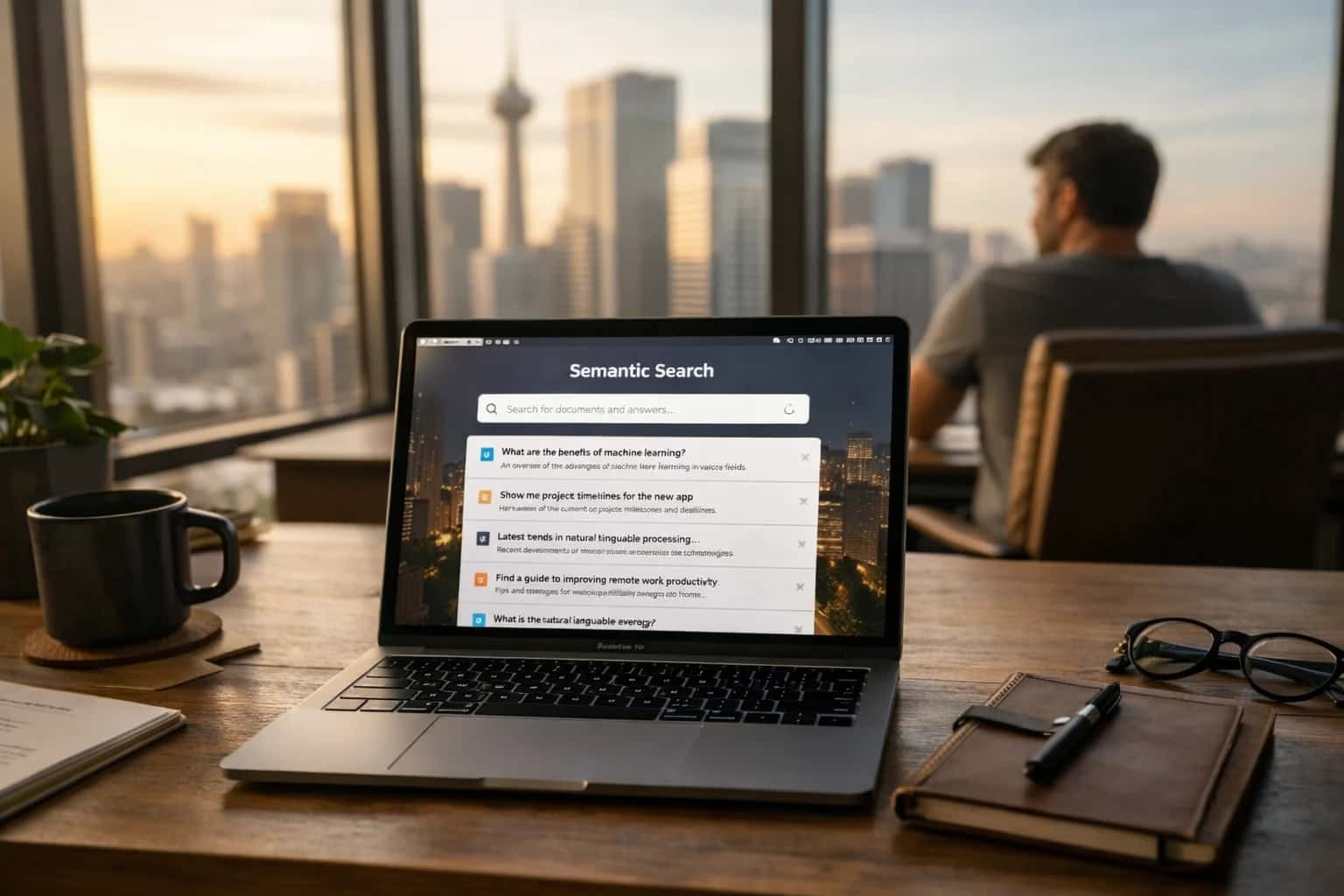
What is Logical Data Fabric?
A logical data fabric is a metadata-driven data management architecture that provides a virtualized, integrated, and semantically consistent view of enterprise data across disparate sources without requiring physical movement or replication.
The core mechanism is semantic integration, where a central ontology or business vocabulary defines the meaning and relationships of data entities, enabling semantic interoperability. A federated query engine decomposes user requests, routes sub-queries to the appropriate sources, and integrates results. This architecture supports data governance, lineage tracking, and serves as a semantic layer for analytics and Retrieval-Augmented Generation (RAG), providing deterministic factual grounding for AI systems without building a physical data warehouse.
LOGICAL DATA FABRIC
Core Architectural Characteristics
A logical data fabric is a metadata-driven data management architecture that provides a virtualized, integrated, and semantically consistent view of data across disparate sources without requiring physical movement or replication.
01
Virtualized Data Access Layer
The core architectural principle of a logical data fabric is data virtualization. It creates a unified, logical data layer that abstracts the physical location and format of source data. This layer provides a single access point for queries, which are then decomposed, routed, and executed against the appropriate source systems (databases, data lakes, APIs) in real-time. Key benefits include:
- Zero data replication: Eliminates the latency, storage costs, and synchronization complexity of ETL-based data warehouses.
- Real-time data access: Applications always query the most current data directly at the source.
- Location transparency: Consumers interact with a logical model, unaware of the underlying data's physical distribution.
02
Semantic Model as the Unifying Schema
A logical data fabric uses a semantic model—typically an ontology or knowledge graph schema—as its canonical business vocabulary. This model defines the entities, attributes, and relationships in business terms. Heterogeneous source data is mapped to this unified model using declarative mapping languages like R2RML or RML. This enables:
- Semantic interoperability: Different systems can exchange data with unambiguous, shared meaning.
- Business-friendly querying: Users and applications can query using business concepts (e.g., "Customer," "Product") instead of technical table and column names.
- Contextual integration: Data from different sources is integrated based on its meaning, not just its structure.
03
Query Federation Engine
The query federation engine is the computational heart of the fabric. It accepts a query expressed against the semantic model, performs query decomposition, and generates optimized sub-queries tailored for each underlying data source (e.g., SQL for a relational database, a REST call for an API, SPARQL for a triplestore). It then federates the execution, retrieves the results, and performs any necessary post-processing (joining, filtering, aggregation) to return a unified result set. This requires sophisticated cost-based optimization to minimize data transfer and latency.
04
Active Metadata Foundation
A logical data fabric is built on a foundation of active metadata. This includes not just technical metadata (schemas, data types) but also business metadata (definitions, owners), operational metadata (lineage, performance stats), and semantic metadata (ontologies, mappings). This metadata is stored in a metadata graph—a knowledge graph of metadata—which the fabric actively uses to:
- Drive query planning and optimization.
- Enable data discovery and governance.
- Provide end-to-end data lineage and provenance tracking for every query result.
05
Comparison to Physical Data Fabrics
It is critical to distinguish a logical fabric from a physical data fabric. A physical fabric often relies on centralized storage (like a data lake) and involves copying or replicating data. In contrast, a logical fabric is decentralized and virtual.
Key Differentiators:
- Data Movement: Logical = None; Physical = Required.
- Latency: Logical = Real-time; Physical = Batch-driven.
- Storage Cost: Logical = Low (metadata only); Physical = High (stores raw data).
- Data Freshness: Logical = Always current; Physical = Stale until next ETL/ELT run.
- Use Case: Logical is ideal for operational analytics, composite applications, and real-time decisioning; Physical is suited for historical analysis and training machine learning models on large, consolidated datasets.
06
Enterprise Integration Pattern
A logical data fabric implements a federated integration pattern. It does not replace existing data systems but sits atop them as a mediation layer. This makes it particularly valuable in complex enterprise environments with:
- Legacy systems that cannot be easily modified or migrated.
- Hybrid/multi-cloud deployments where data is spread across different providers and on-premises systems.
- Strict data sovereignty or residency requirements that prevent data from being moved to a central location.
- Autonomous domain teams (as in a Data Mesh) that own their data products; the fabric provides a global, discoverable view without centralizing control.
ARCHITECTURAL OVERVIEW
How a Logical Data Fabric Works
A logical data fabric is a metadata-driven architecture that provides a virtualized, integrated view of enterprise data across disparate sources without requiring physical movement or replication.
A logical data fabric creates a unified semantic layer by using a knowledge graph to model business concepts and their relationships. This virtual layer sits above distributed data sources—like databases, data lakes, and APIs—and uses semantic mappings (e.g., R2RML, RML) to translate queries in real-time. The core engine performs query federation, decomposing a single business question, executing sub-queries against the appropriate sources, and integrating the results. This provides a single source of truth without the latency and cost of building a physical data warehouse.
The architecture relies on a semantic catalog and a metadata graph to maintain a live inventory of data assets, their lineage, and business context. This enables semantic interoperability, allowing different systems to exchange data with shared meaning. Key capabilities include data virtualization for real-time access and semantic governance to ensure consistency. Unlike a physical data fabric, it emphasizes agility and logical integration, making it foundational for Graph-Based RAG and explainable AI systems that require deterministic, context-aware data retrieval.
ARCHITECTURE COMPARISON
Logical Data Fabric vs. Related Architectures
A technical comparison of the Logical Data Fabric with other prominent data management architectures, highlighting key differences in design philosophy, implementation, and governance.
| Architectural Feature / Capability | Logical Data Fabric | Data Mesh | Traditional Data Warehouse | Data Lake |
|---|---|---|---|---|
Core Design Principle | Virtualized, semantic integration layer | Decentralized, domain-oriented data products | Centralized, schema-on-write storage | Centralized, schema-on-read storage |
Primary Integration Method | Query federation & semantic mapping | Domain-owned APIs & product contracts | ETL/ELT batch pipelines | Data ingestion & file storage |
Data Movement / Replication | ||||
Unified Semantic Layer | ||||
Real-Time Data Access | ||||
Governance Model | Centralized semantic governance | Federated computational governance | Centralized IT governance | Centralized or ad-hoc governance |
Primary Query Interface | Graph query (SPARQL) & SQL | Domain-specific APIs | SQL | SQL & programmatic (Spark, etc.) |
Metadata Management | Active metadata graph with lineage | Decentralized data product registries | Centralized technical metadata | Catalog as an afterthought |
Business Logic Location | Centralized in semantic models & mappings | Embedded within domain data products | Centralized in ETL & BI models | In downstream processing jobs |
Optimal For Use Case | Enterprise-wide integrated queries & analytics | Independent, scalable domain analytics | Structured historical reporting | Large-scale raw data storage & exploration |
LOGICAL DATA FABRIC
Enterprise Use Cases
A logical data fabric provides a virtualized, integrated view of enterprise data without physical consolidation. These cards detail its primary applications in solving complex business challenges.
01
Unified Customer 360 View
A logical data fabric creates a virtual golden record of a customer by federating queries across CRM, support ticketing, e-commerce, and marketing automation systems. This provides a real-time, holistic view without the latency and data duplication of traditional ETL.
- Key Benefit: Enables hyper-personalized marketing and support by accessing the most current data from each source system.
- Example: A service agent instantly sees a customer's recent orders (from the ERP), open support tickets (from Zendesk), and campaign engagement (from Marketo) in a single interface.
02
Regulatory Compliance & Reporting
Enterprises use a logical data fabric to generate auditable reports that pull data from siloed financial, HR, and operational systems on-demand. It enforces semantic governance by applying consistent business rules and definitions across all federated sources.
- Key Benefit: Dramatically reduces the time and risk associated with manual report consolidation for regulations like GDPR, SOX, or Basel III.
- Example: An automated quarterly financial report is generated by querying SAP ERP for transactions, Workday for HR costs, and a custom billing database, with all currency conversions and accruals applied uniformly.
03
Real-Time Supply Chain Intelligence
By providing a virtual layer over IoT sensor data, warehouse management systems, logistics partner APIs, and demand forecasting models, a logical data fabric enables dynamic supply chain orchestration.
- Key Benefit: Allows for real-time exception handling, such as rerouting shipments around a port delay, by correlating live data streams.
- Example: A query identifies all shipments containing a recalled component by joining IoT telemetry (from trucks), inventory records (from WMS), and supplier manifests (from an EDI system) without moving terabytes of data.
04
Clinical Research & Healthcare Analytics
In healthcare, a logical data fabric enables privacy-preserving federated queries across electronic health records (EHRs), genomic databases, clinical trial management systems, and insurance claims. It uses a semantic layer to align disparate medical ontologies (like SNOMED CT and ICD-10).
- Key Benefit: Accelerates cohort discovery for clinical trials and longitudinal studies while maintaining strict data residency and HIPAA compliance.
- Example: Researchers identify potential trial participants by querying for patients with specific genetic markers (from a lab system) and treatment histories (from Epic or Cerner EHRs) without centralizing Protected Health Information (PHI).
05
Financial Fraud Detection
Banks deploy logical data fabrics to perform cross-channel fraud analysis in real-time. A single query can correlate credit card transactions (payment network), account login patterns (identity management), customer profiles (core banking), and historical alert logs (SIEM).
- Key Benefit: Detects sophisticated, multi-vector fraud schemes (e.g., account takeover followed by rapid micro-transactions) that are invisible when analyzing systems in isolation.
- Example: A federated query flags a transaction by joining: a login from a new device (Okta), a small test transaction (VisaNet), and a recent address change request (Salesforce CRM) within a 5-minute window.
06
Mergers & Acquisitions (M&A) Integration
During post-merger integration, a logical data fabric provides immediate business intelligence across legacy systems without the multi-year project of physically merging IT infrastructures. It creates a virtual single source of truth for leadership.
- Key Benefit: Delivers operational visibility and combined reporting within weeks, not years, accelerating synergy realization and decision-making.
- Example: Leadership views combined sales pipelines by federating data from the acquiring company's Salesforce instance and the target company's legacy Microsoft Dynamics CRM, using a unified semantic model for 'opportunity' and 'customer'.
LOGICAL DATA FABRIC
Frequently Asked Questions
A logical data fabric is a metadata-driven architecture that provides a virtualized, integrated view of enterprise data without physical consolidation. These questions address its core mechanisms, benefits, and differentiation from related data management paradigms.
A logical data fabric is a data management architecture that provides a unified, virtualized view of data across disparate sources—such as databases, data lakes, and APIs—without physically moving or replicating the underlying data. It works by using a semantic layer, typically built on a knowledge graph or ontology, to create a business-friendly, conceptual model of all connected data assets. When a query is issued, the fabric's query federation engine decomposes it, routes sub-queries to the appropriate source systems in real-time, and integrates the results, presenting them as if from a single source. This is enabled by mapping definitions (e.g., using R2RML or RML) that translate heterogeneous source schemas into a common semantic model.
Enabling Efficiency, Speed & Accuracy
Intelligent Analysis, Decision & Execution
We build AI systems for teams that need search across company data, workflow automation across tools, or AI features inside products and internal software.
Talk to Us
Search across company data
Give teams answers from docs, tickets, runbooks, and product data with sources and permissions.
Useful when people spend too long searching or get different answers from different systems.
Enterprise searchRAGPermissions
Read more
Automate internal workflows
Use AI to route work, draft outputs, trigger actions, and keep approvals and logs in place.
Useful when repetitive work moves across multiple tools and teams.
AI agentsWorkflow automationGovernance
Read more
Add AI to products and internal tools
Build assistants, guided actions, or decision support into the software your team or customers already use.
Useful when AI needs to be part of the product, not a separate tool.
AI integrationDecision supportModel routing
Read more
About the author
Prasad Kumkar
CEO & MD, Inference Systems
Prasad Kumkar is the CEO & MD of Inference Systems and writes about AI systems architecture, LLM infrastructure, model serving, evaluation, and production deployment. Over 5+ years, he has worked across computer vision models, L5 autonomous vehicle systems, and LLM research, with a focus on taking complex AI ideas into real-world engineering systems.
His work and writing cover AI systems, large language models, AI agents, multimodal systems, autonomous systems, inference optimization, RAG, evaluation, and production AI engineering.
LinkedIn
Limited slotsGet a Free AI Consultation
Partnered with leading AI, data, and software stack.
























How We Work
Custom AI workflows for your Business
One-fit-all AI don't work for modern businesses. At Inferensys, we aim to understand your business & custom requirements; which we use to define most efficient agentic workflows, the data, and the tools for your business.
01
Review the use case
We understand the task, the users, and where AI can actually help.
Read more02
Pick the right approach
We define what needs search, automation, or product integration.
Read more03
Build the first useful version
We implement the part that proves the value first.
Read more04
Improve from there
We add the checks and visibility needed to keep it useful.
Read moreThe first call is a practical review of your use case and the right next step.
Talk to Us