Schema-Aware Decoding is an inference-time algorithm where a language model's token-by-token generation is dynamically guided by a live representation of an output schema (e.g., JSON Schema) to guarantee syntactic and structural validity. Unlike simple post-generation validation, it actively constrains the model's token vocabulary at each step, preventing illegal tokens that would break the target format. This technique is a core method for structured output generation, ensuring machine-readable outputs like JSON or XML are produced correctly on the first attempt, eliminating parsing failures.
Glossary
Schema-Aware Decoding
Schema-Aware Decoding is an inference-time algorithm that dynamically guides a language model's token generation using a live schema representation to guarantee syntactically and semantically valid structured outputs.
STRUCTURED OUTPUT GENERATION
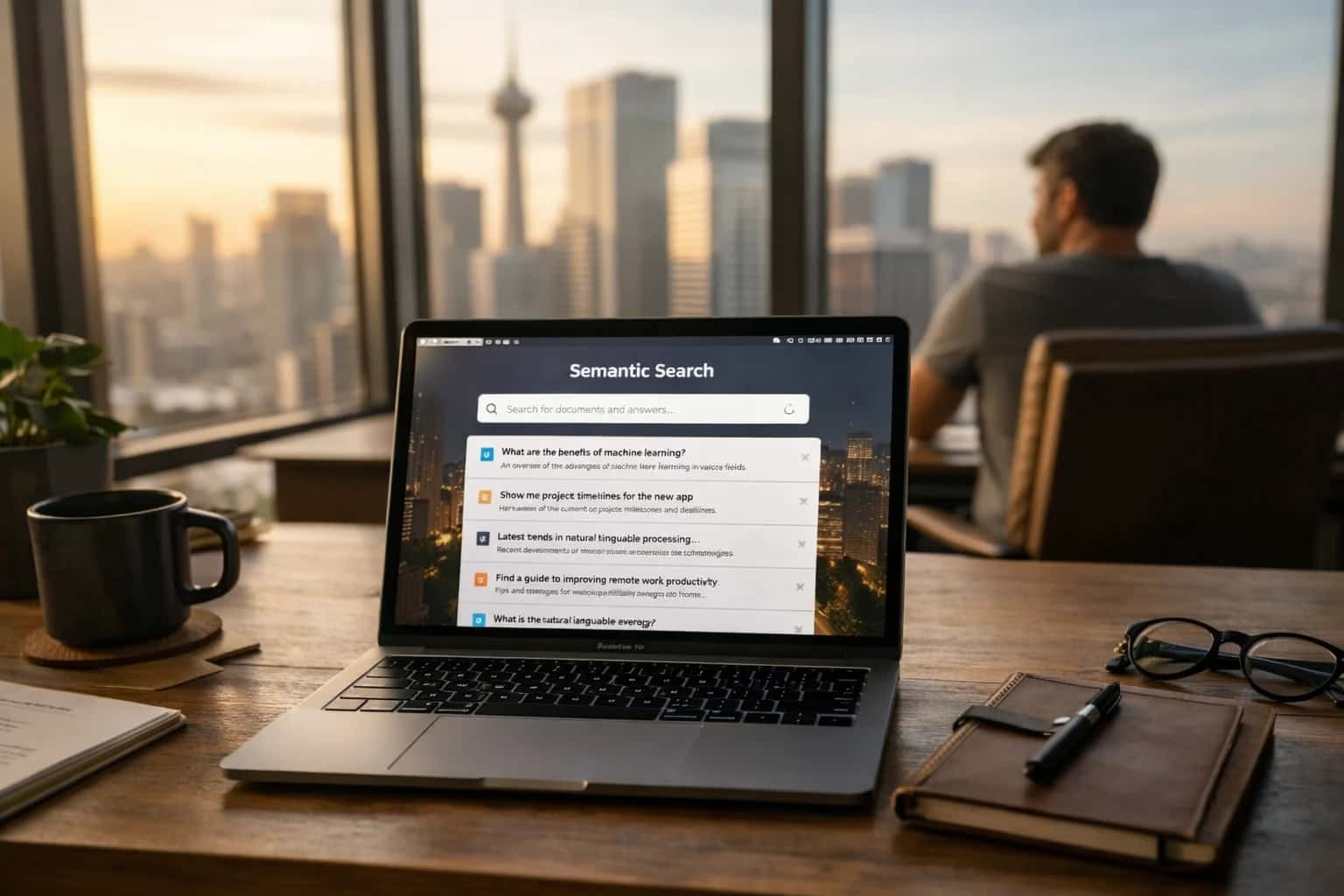
What is Schema-Aware Decoding?
A constrained decoding technique that guarantees a language model's output conforms to a predefined data schema.
The algorithm typically works by integrating a state machine or parser that tracks the model's position within the schema during generation. This allows it to enforce required fields, data types (string, number, boolean), and nested structures in real-time. It is closely related to grammar-based decoding and is a sophisticated form of constrained decoding. By providing a formal guarantee on output shape, it enables reliable integration of LLMs into downstream software systems, forming a critical data contract between the AI and application code.
INFERENCE-TIME ALGORITHM
Key Features of Schema-Aware Decoding
Schema-Aware Decoding is an inference-time algorithm where a language model's token generation is dynamically guided by a live representation of the output schema to guarantee syntactic and semantic validity.
01
Live Token Masking
The core mechanism where the decoder dynamically restricts the model's vocabulary at each generation step. An automaton or finite-state machine, built from the target schema (e.g., JSON Schema), determines which tokens are valid next choices. This prevents syntax errors like missing commas, unmatched braces, or invalid keywords from ever being generated.
- Example: When generating a JSON object, after an opening curly brace
{, only a closing brace}or a valid string key (from the schema'sproperties) are permitted tokens.
02
Type-Constrained Generation
Ensures generated values strictly adhere to the data types defined in the schema. The algorithm enforces type-specific token patterns.
- String Values: Must be generated within quotation marks.
- Numbers: Must follow valid numeric token sequences (digits, optional decimal point, optional minus sign).
- Booleans: Restricted to the tokens for
trueorfalse. - Null: Restricted to the token
null.
This eliminates common post-processing failures where a model outputs yes instead of true or an unquoted string.
03
Structural Validity Guarantee
Guarantees the hierarchical shape of the output matches the schema. The algorithm tracks the generation state to enforce nesting and cardinality rules.
- Object/Array Nesting: Ensures correct opening and closing of
{}and[]. - Required Properties: Prevents generation from finishing until all schema-defined
requiredfields have been produced. - Array Length: Can enforce minimum or maximum item counts if specified in the schema.
The output is deterministically parseable by standard libraries like json.loads() on the first attempt, with no need for retries or "JSON repair."
04
Integration with Sampling
Works alongside standard sampling techniques (nucleus, temperature) without eliminating creativity within constraints. The algorithm biases the logits (token probabilities) of the model, typically by setting the probabilities of invalid next tokens to -inf. Valid tokens within the masked set are still sampled according to the model's learned distribution.
- This allows for semantic variation (e.g., generating different, valid city names for a
"city"field) while maintaining syntactic rigidity. - It is distinct from simple post-hoc filtering, as the invalid paths are never explored, improving efficiency.
05
Schema Compilation
The prerequisite step where a human-readable schema (like JSON Schema) is compiled into a format the decoder can efficiently query during generation. This often involves converting the schema into a pushdown automaton or a parsing expression grammar (PEG).
- This compiled representation allows for O(1) validity checks at each token position.
- Libraries like Outline (for JSON Schema) or Guidance (for custom grammars) perform this compilation. The complexity of the schema directly impacts the initial compilation time, not the per-token generation overhead.
06
Contrast with Post-Processing
Highlights the fundamental advantage over naive approaches. Schema-Aware Decoding is a preventive technique, while Output Validation and JSON Repair are corrective.
| Aspect | Schema-Aware Decoding | Post-Processing/Repair |
|---|---|---|
| Latency | Slight overhead per token. | Full generation latency + repair latency. |
| Guarantee | 100% valid output by construction. | Attempts to fix invalid output; may fail. |
| Retry Loops | Eliminated. | Often required, increasing cost and latency. |
| Data Loss | None. | Possible during repair of garbled output. |
TECHNIQUE COMPARISON
Schema-Aware Decoding vs. Other Structured Output Techniques
A comparison of inference-time methods for generating structured outputs like JSON, focusing on validity guarantees, implementation complexity, and performance.
| Feature / Metric | Schema-Aware Decoding | Grammar-Based Decoding | Structured Prompting | Post-Processing & Parsing |
|---|---|---|---|---|
Core Mechanism | Dynamic token biasing using a live schema representation | Formal grammar (e.g., CFG) restricting valid token sequences | In-context examples and explicit format instructions in the prompt | Rule-based extraction and validation after free-form generation |
Validity Guarantee | High - Ensures output is structurally and type-valid against schema | High - Guarantees syntactic validity against the defined grammar | Low - Relies on model's instruction-following; prone to format drift | None - Assumes raw text can be parsed; requires error handling |
Implementation Complexity | High - Requires integration with model's sampling loop and schema compiler | Medium - Requires a grammar definition and integration with decoder | Low - Purely a prompt engineering task | Low to Medium - Requires robust parsing and validation scripts |
Inference Latency Impact | Medium - Adds computational overhead for schema validation during generation | Low to Medium - Efficient finite-state automata guide generation | None - No change to base model inference | None - Processing occurs after inference is complete |
Schema Flexibility | High - Supports complex JSON Schema with nested objects, arrays, and type constraints | Medium - Excellent for syntax; type validation often requires post-check | Low - Complex, nested schemas are difficult to communicate reliably | N/A - Applied after the fact to any output |
Developer Experience | Declarative - Define JSON Schema; validity is handled automatically | Technical - Requires defining a formal grammar in EBNF or similar | Accessible - No code changes; iterative prompt tuning | Reactive - Must write code to handle many edge cases and failures |
Integration with Tool Calling | Native - Schema often derived from function/tool definitions | Possible - Grammar can be generated from a tool signature | Manual - Must describe the tool call format in natural language | Manual - Must parse a natural language description of a tool call |
Typical Use Case | Guaranteeing API-ready JSON for downstream systems | Ensuring syntactically correct code, SQL, or JSON | Rapid prototyping or tasks with simple, consistent formats | Legacy integration or when model choice lacks structured output features |
SCHEMA-AWARE DECODING
Frameworks and Provider Implementations
Schema-Aware Decoding is implemented across major inference engines and cloud APIs to provide deterministic structured output. This section details the key frameworks and provider features that enable this capability.
SCHEMA-AWARE DECODING
Frequently Asked Questions
Schema-Aware Decoding is an advanced inference-time technique that ensures language model outputs conform to a predefined structure. This FAQ addresses its core mechanisms, benefits, and practical applications for developers.
Schema-Aware Decoding is an inference-time algorithm where a language model's token generation is dynamically guided by a live, in-memory representation of an output schema (like JSON Schema) to guarantee syntactic and structural validity. Unlike post-generation validation, it intervenes during the sampling process, preventing invalid tokens from being selected in the first place. This is achieved by integrating a finite-state machine or a pushdown automaton that represents the schema's grammar, which the decoder consults at each generation step to determine the set of permissible next tokens. The core guarantee is that the raw output string is deterministically parseable by a standard parser for the target format, eliminating formatting errors and enabling reliable integration with downstream APIs and databases.
Enabling Efficiency, Speed & Accuracy
Intelligent Analysis, Decision & Execution
We build AI systems for teams that need search across company data, workflow automation across tools, or AI features inside products and internal software.
Talk to Us
Search across company data
Give teams answers from docs, tickets, runbooks, and product data with sources and permissions.
Useful when people spend too long searching or get different answers from different systems.
Enterprise searchRAGPermissions
Read more
Automate internal workflows
Use AI to route work, draft outputs, trigger actions, and keep approvals and logs in place.
Useful when repetitive work moves across multiple tools and teams.
AI agentsWorkflow automationGovernance
Read more
Add AI to products and internal tools
Build assistants, guided actions, or decision support into the software your team or customers already use.
Useful when AI needs to be part of the product, not a separate tool.
AI integrationDecision supportModel routing
Read more
About the author
Prasad Kumkar
CEO & MD, Inference Systems
Prasad Kumkar is the CEO & MD of Inference Systems and writes about AI systems architecture, LLM infrastructure, model serving, evaluation, and production deployment. Over 5+ years, he has worked across computer vision models, L5 autonomous vehicle systems, and LLM research, with a focus on taking complex AI ideas into real-world engineering systems.
His work and writing cover AI systems, large language models, AI agents, multimodal systems, autonomous systems, inference optimization, RAG, evaluation, and production AI engineering.
LinkedIn
Limited slotsGet a Free AI Consultation
Partnered with leading AI, data, and software stack.
























How We Work
Custom AI workflows for your Business
One-fit-all AI don't work for modern businesses. At Inferensys, we aim to understand your business & custom requirements; which we use to define most efficient agentic workflows, the data, and the tools for your business.
01
Review the use case
We understand the task, the users, and where AI can actually help.
Read more02
Pick the right approach
We define what needs search, automation, or product integration.
Read more03
Build the first useful version
We implement the part that proves the value first.
Read more04
Improve from there
We add the checks and visibility needed to keep it useful.
Read moreThe first call is a practical review of your use case and the right next step.
Talk to Us