Time-warping is a class of algorithms, most notably Dynamic Time Warping (DTW), that measures similarity between two temporal sequences by finding an optimal non-linear alignment between them. This allows for robust comparison even when sequences are out of phase, have different speeds, or contain local accelerations and decelerations. In agentic memory systems, it enables the matching of past behavioral sequences or event streams to current situations, facilitating pattern recognition and analogical reasoning over time.
Glossary
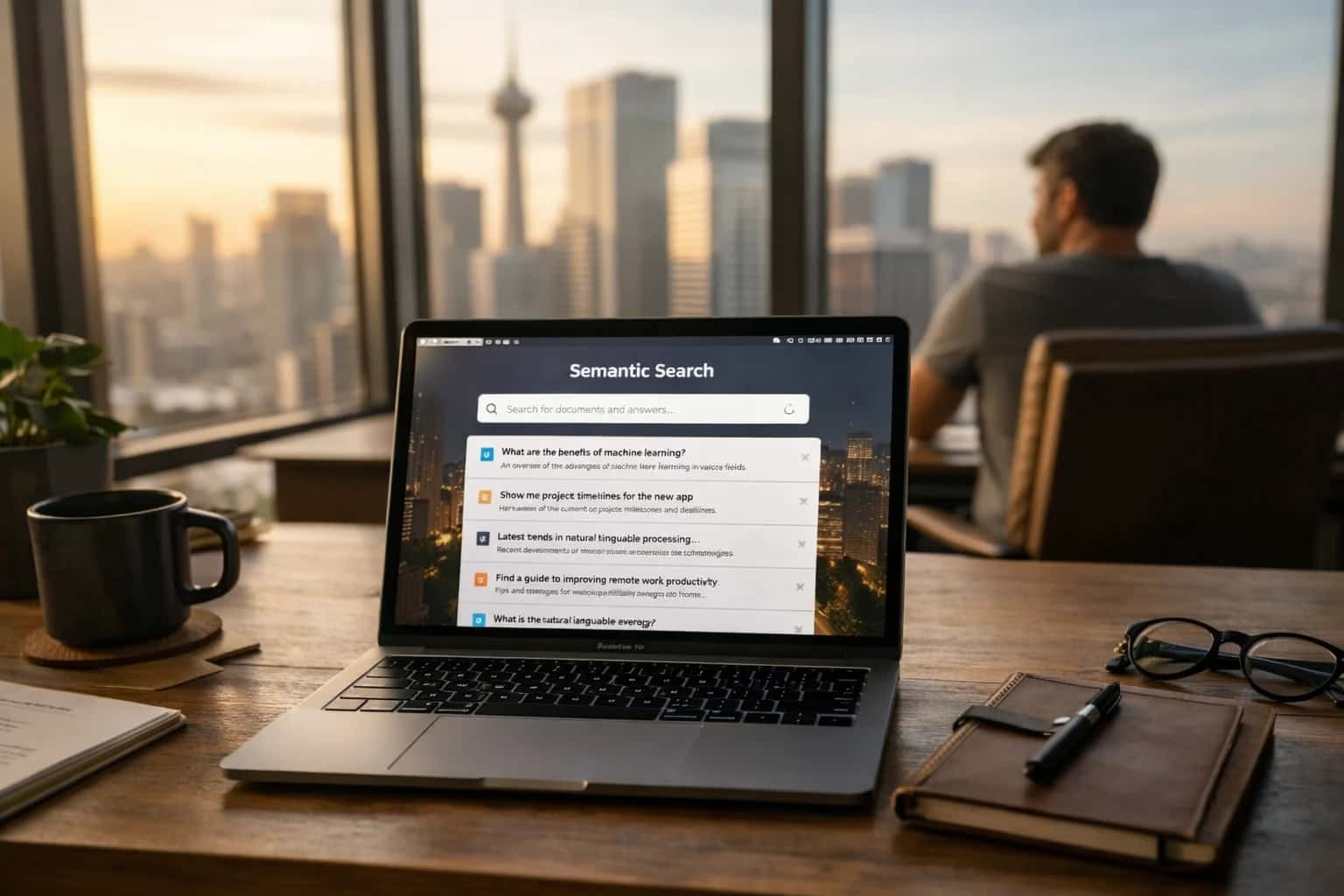
Time-Warping
Time-Warping is a computational technique for measuring similarity between two temporal sequences that may vary in speed or local timing, such as Dynamic Time Warping (DTW).
TEMPORAL MEMORY SEQUENCING
What is Time-Warping?
A computational technique for aligning and comparing sequences that vary in speed or local timing.
The technique works by constructing a cost matrix to evaluate all possible alignments and then finding the path with minimal cumulative distance, effectively 'warping' the time axis of one sequence to match the other. Beyond DTW, related methods include sequence alignment algorithms from bioinformatics and temporal convolution in neural networks. For autonomous agents, this is critical for tasks like anomaly detection in sensor logs, aligning multi-modal experiences, or retrieving past episodes based on the shape of an event sequence rather than exact timestamps.
TEMPORAL MEMORY SEQUENCING
Core Characteristics of Time-Warping
Time-warping refers to a class of algorithms, most notably Dynamic Time Warping (DTW), designed to measure similarity between two temporal sequences that may vary in speed or local timing. It is a foundational technique for aligning and comparing event streams, sensor data, and other sequential memories in agentic systems.
01
Non-Linear Alignment
Unlike Euclidean distance, which compares sequences point-by-point, Dynamic Time Warping (DTW) finds an optimal non-linear alignment between two sequences by warping the time axis. This allows it to match similar shapes in the data even if they are stretched, compressed, or locally shifted in time.
- Key Mechanism: Computes a cost matrix and finds the minimum-cost warping path.
- Use Case: Aligning speech patterns of different speakers, matching sensor readings from equipment operating at variable speeds, or comparing agent action histories.
02
Invariance to Local Time Shifts
A core strength of time-warping is its invariance to local timing distortions. It is robust to:
- Temporal Scaling: Sequences that unfold faster or slower overall.
- Local Stretching/Compression: Variations in the duration of specific sub-sequences or events.
- Phase Shifts: Similar events occurring at slightly different absolute times.
This makes it ideal for temporal memory retrieval, where an agent's past experience may not perfectly align in time with a current situation but shares the same sequential pattern.
03
Computational Complexity and Optimizations
The classic DTW algorithm has O(n*m) time and space complexity, where n and m are the lengths of the two sequences. This can be prohibitive for long sequences. Common optimizations include:
- Windowing Constraints (Sakoe-Chiba Band, Itakura Parallelogram): Restrict the warping path to a band around the diagonal.
- Lower Bounding Techniques: Use fast lower-bound estimates (e.g., LB_Keogh) to prune expensive full DTW calculations.
- Approximation Algorithms: Use faster, approximate methods like FastDTW.
- Early Abandonment: Stop the cost calculation if it exceeds a known threshold.
04
Application in Agentic Memory
In Temporal Memory Sequencing, time-warping enables agents to find analogous past episodes. For an autonomous warehouse robot, DTW could match its current sensor stream (e.g., LIDAR, encoder ticks) against a library of past successful navigation event streams, even if the current execution is slower due to battery drain or obstacle avoidance.
It bridges Sequential Memory and Time-Aware Retrieval, allowing agents to reason by temporal analogy rather than exact timestamp matching.
05
Relation to Other Temporal Techniques
Time-warping is part of a broader toolkit for temporal analysis:
- Contrast with Sequence Alignment: While related, DTW is a similarity measure for real-valued sequences, whereas sequence alignment (e.g., Needleman-Wunsch) is often for discrete symbols with gap penalties.
- Foundation for Temporal Embedding: Warped sequences can be used to generate more meaningful temporal embeddings for similarity search.
- Preprocessing for Event Causality Graphs: Aligned sequences help identify correlated events for building event causality graphs.
- Complement to Temporal Convolutional Networks (TCNs): TCNs extract features; DTW compares the resulting feature sequences.
06
Limitations and Practical Considerations
Despite its power, time-warping has key limitations:
- Sensitivity to Noise: Outliers can distort the warping path. Pre-processing with smoothing or outlier removal is often required.
- Not a Metric: Basic DTW does not satisfy the triangle inequality, complicating its use in some indexing structures.
- Choice of Distance Function: The local cost function (often Euclidean, Manhattan, or squared difference) significantly impacts results.
- Global vs. Local Warping: Unconstrained warping may produce unintuitive alignments. Constraints are usually necessary for domain-specific validity.
These factors require careful tuning when integrating DTW into production agentic memory systems.
TEMPORAL MEMORY SEQUENCING
Frequently Asked Questions
Time-warping is a foundational technique for comparing temporal sequences in AI systems. These FAQs address its core mechanisms, applications, and relationship to broader memory architectures.
Dynamic Time Warping (DTW) is an algorithm that calculates an optimal alignment between two temporal sequences that may vary in speed or local timing, providing a measure of their similarity. It works by constructing a cost matrix where each cell (i, j) represents the distance (e.g., Euclidean) between point i in the first sequence and point j in the second. The algorithm then finds the warping path—a path through this matrix from the start (1,1) to the end (n,m)—that minimizes the cumulative distance, allowing one sequence to be "stretched" or "compressed" non-linearly along its time axis to match the other. This path defines how points in one sequence correspond to points in the other, bypassing strict one-to-one, time-indexed matching.
Key steps include:
- Cost Matrix Computation: Calculate the local distance between every pair of points.
- Accumulated Cost Matrix: Apply dynamic programming to find the minimum cumulative cost to reach each cell, using the recurrence:
D(i,j) = d(i,j) + min( D(i-1,j), D(i,j-1), D(i-1,j-1) ). - Path Backtracking: Trace back from
D(n,m)toD(1,1)to find the optimal warping path.
Enabling Efficiency, Speed & Accuracy
Intelligent Analysis, Decision & Execution
We build AI systems for teams that need search across company data, workflow automation across tools, or AI features inside products and internal software.
Talk to Us
Search across company data
Give teams answers from docs, tickets, runbooks, and product data with sources and permissions.
Useful when people spend too long searching or get different answers from different systems.
Enterprise searchRAGPermissions
Read more
Automate internal workflows
Use AI to route work, draft outputs, trigger actions, and keep approvals and logs in place.
Useful when repetitive work moves across multiple tools and teams.
AI agentsWorkflow automationGovernance
Read more
Add AI to products and internal tools
Build assistants, guided actions, or decision support into the software your team or customers already use.
Useful when AI needs to be part of the product, not a separate tool.
AI integrationDecision supportModel routing
Read more
About the author
Prasad Kumkar
CEO & MD, Inference Systems
Prasad Kumkar is the CEO & MD of Inference Systems and writes about AI systems architecture, LLM infrastructure, model serving, evaluation, and production deployment. Over 5+ years, he has worked across computer vision models, L5 autonomous vehicle systems, and LLM research, with a focus on taking complex AI ideas into real-world engineering systems.
His work and writing cover AI systems, large language models, AI agents, multimodal systems, autonomous systems, inference optimization, RAG, evaluation, and production AI engineering.
LinkedIn
Limited slotsGet a Free AI Consultation
Partnered with leading AI, data, and software stack.
























How We Work
Custom AI workflows for your Business
One-fit-all AI don't work for modern businesses. At Inferensys, we aim to understand your business & custom requirements; which we use to define most efficient agentic workflows, the data, and the tools for your business.
01
Review the use case
We understand the task, the users, and where AI can actually help.
Read more02
Pick the right approach
We define what needs search, automation, or product integration.
Read more03
Build the first useful version
We implement the part that proves the value first.
Read more04
Improve from there
We add the checks and visibility needed to keep it useful.
Read moreThe first call is a practical review of your use case and the right next step.
Talk to Us