A Semantic Memory Layer is a structured, long-term memory component within an autonomous agent that stores general world knowledge, facts, concepts, and their interrelationships, independent of specific episodic experiences. It functions as a persistent knowledge base, enabling the agent to reason about abstract concepts and apply learned information to novel situations. This layer is typically implemented using technologies like vector databases or knowledge graphs to facilitate efficient, similarity-based retrieval of semantically relevant information.
Glossary
Semantic Memory Layer
A semantic memory layer is a structured component in an AI agent that stores general world knowledge, facts, concepts, and their relationships, enabling reasoning independent of specific personal experiences.
HIERARCHICAL MEMORY STRUCTURES
What is a Semantic Memory Layer?
A core component in agentic AI architectures responsible for storing and retrieving general world knowledge and conceptual relationships.
Unlike an Episodic Memory Module that records specific events, the semantic layer captures decontextualized, factual knowledge (e.g., "Paris is the capital of France"). It works in concert with a Working Memory Buffer for immediate task context and is a critical part of a Hierarchical Memory architecture. Its primary engineering challenge is balancing retrieval speed, storage scalability, and the accuracy of semantic similarity searches to provide grounded, factual context for an agent's decision-making processes.
ARCHITECTURAL PRINCIPLES
Key Characteristics of a Semantic Memory Layer
A semantic memory layer is a structured, persistent component within an agentic architecture that stores general world knowledge, facts, concepts, and their interrelationships. Unlike episodic memory, it is independent of specific personal experiences and is optimized for conceptual reasoning and factual grounding.
01
Conceptual & Factual Storage
This layer stores declarative knowledge—facts about the world (e.g., 'Paris is the capital of France') and conceptual relationships (e.g., 'a mammal is an animal'). Its primary function is to provide a persistent knowledge base that an agent can query to ground its reasoning in verifiable information, independent of any specific event or experience.
- Examples: Company org charts, product specifications, domain ontologies, historical dates.
- Contrast: Differs from episodic memory, which stores 'I met the CEO last Tuesday,' and procedural memory, which stores 'how to format a JSON API response.'
02
Structured Representation
Information is not stored as raw text but in a structured format that encodes meaning and relationships. The two dominant paradigms are:
- Vector-Based (Embeddings): Concepts are encoded as high-dimensional vectors in a dense vector space, where semantic similarity corresponds to geometric proximity. Enables fast approximate nearest neighbor (ANN) search.
- Graph-Based (Knowledge Graphs): Concepts are stored as entities (nodes) and their relationships (edges) defined by a schema or ontology. Enables complex, multi-hop reasoning queries (e.g., 'Which projects did employees in the Berlin office work on?').
Hybrid approaches combine both for retrieval and reasoning.
03
Semantic Retrieval Interface
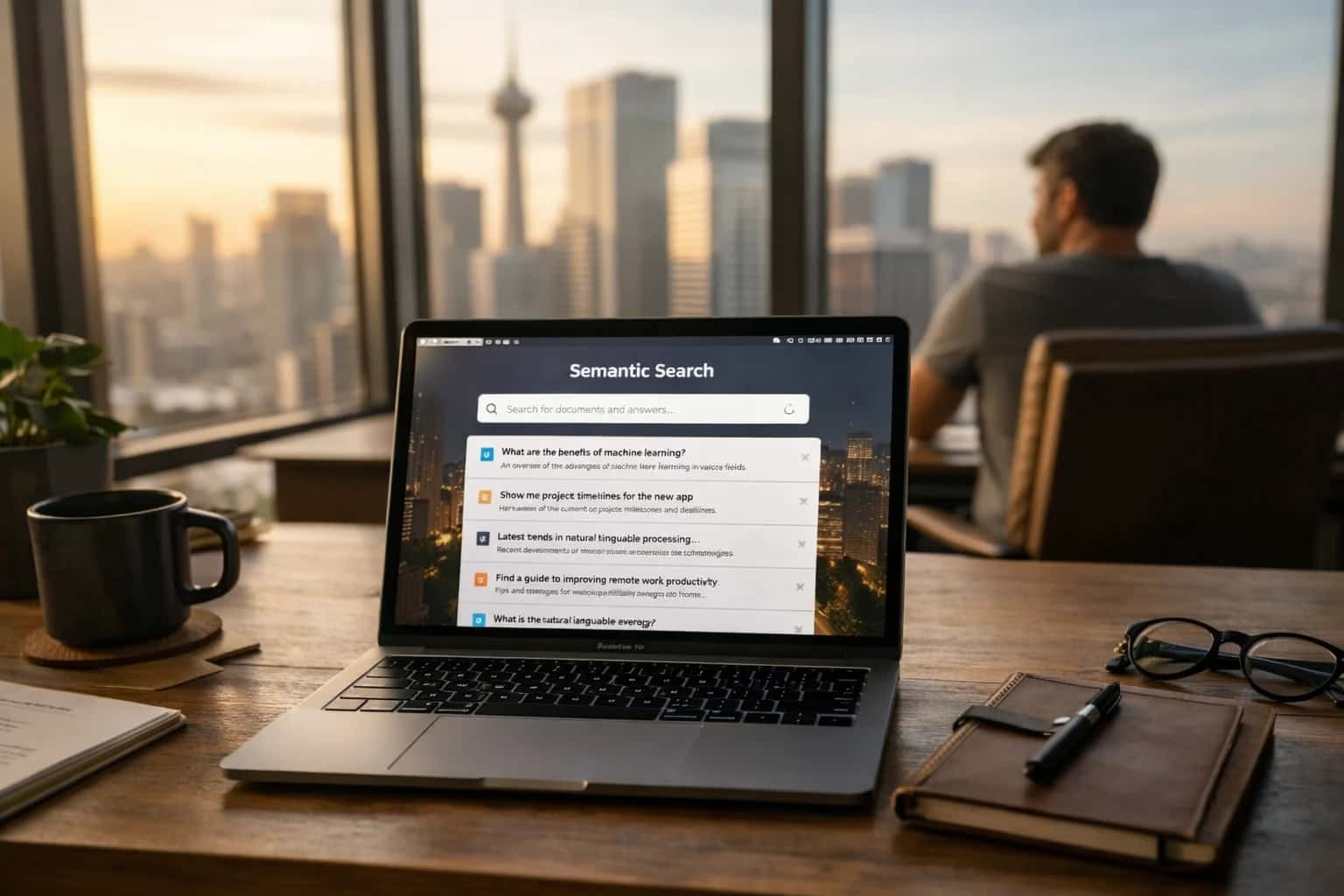
Access is via semantic search, not keyword lookup. The layer provides an interface where queries in natural language (or as an embedding) retrieve relevant facts based on meaning and context.
- Mechanism: A query ('Tell me about European capitals') is embedded, and the system retrieves stored vectors or graph nodes with the highest semantic similarity.
- Key Benefit: Enables associative recall—finding relevant information even if the exact terms are not present in the query or stored data.
- Integration Point: This retrieval mechanism is a core component of Retrieval-Augmented Generation (RAG) architectures, providing factual context to a large language model.
04
Durability & Independence from Context
Semantic memory is persistent and survives across agent sessions, unlike a working memory buffer. It is also context-independent; the knowledge 'water boils at 100°C' is stored and retrieved without reference to a specific time the agent learned it.
- Storage Backend: Typically implemented using vector databases (e.g., Pinecone, Weaviate) or graph databases (e.g., Neo4j) for long-term persistence.
- System Role: Acts as the agent's long-term factual repository, separate from the transient state of its current task (context window) or its personal history (episodic memory).
05
Integration with Other Memory Types
In a hierarchical memory structure, the semantic layer does not operate in isolation. It interacts with other memory subsystems:
- Feeds Working Memory: Retrieved facts are loaded into the agent's limited context window for immediate reasoning.
- Informs Episodic Memory: General knowledge ('what a meeting is') helps structure and interpret specific episodes ('the 2 PM project sync').
- Supports Procedural Memory: Facts ('the API endpoint is /v1/update') guide the execution of skills ('how to call an API').
The semantic layer provides the conceptual scaffolding upon which other memory types build.
06
Dynamic Updating & Consistency
While stable, a semantic memory layer must be updateable to reflect new knowledge or correct errors. This requires versioning, consistency checks, and update strategies.
- Challenges: Avoiding catastrophic forgetting of old facts when adding new ones and managing conflicting information.
- Update Mechanisms: Can range from manual curation and batch embeddings updates to automated pipelines triggered by trusted sources.
- Governance: In enterprise settings, updates often require validation and audit trails to maintain the knowledge base's integrity, linking to AI governance pillars.
IMPLEMENTATION
How is a Semantic Memory Layer Implemented?
A semantic memory layer is implemented by creating a structured, queryable knowledge store that captures general facts, concepts, and their relationships, enabling an agent to reason about the world beyond its immediate context.
Implementation begins with knowledge representation, where facts and concepts are encoded as structured data. Common approaches include knowledge graphs (using RDF or property graphs) and vector embeddings generated by transformer models. This creates a persistent, indexed store separate from the agent's working memory buffer and episodic memory module. The layer is populated via batch ingestion from curated corpora or through continuous learning from agent interactions, with strict validation to ensure factual integrity.
Access is mediated by a retrieval interface that supports complex queries, such as graph traversals for relationships or semantic search via vector similarity. For integration, the layer exposes APIs that allow the agent's reasoning core to retrieve relevant knowledge to ground its decisions. Consistency mechanisms and versioning are critical to manage updates, while access control enforces data governance, isolating proprietary knowledge from general world facts within the same architecture.
SEMANTIC MEMORY LAYER
Frequently Asked Questions
Essential questions about the semantic memory layer, a core component for storing and reasoning with general world knowledge in autonomous AI agents.
A semantic memory layer is a structured, long-term memory component within an agentic AI system that stores general world knowledge, facts, concepts, and their interrelationships, independent of specific personal experiences or episodic events. It functions as a persistent repository of declarative knowledge, enabling an agent to reason about concepts like "capital cities," "chemical properties," or "business processes" without needing to recall where or when it learned them. This layer is typically implemented using technologies like vector databases for similarity-based retrieval or knowledge graphs for structured relational queries, allowing the agent to ground its reasoning in a consistent, factual foundation.
Enabling Efficiency, Speed & Accuracy
Intelligent Analysis, Decision & Execution
We build AI systems for teams that need search across company data, workflow automation across tools, or AI features inside products and internal software.
Talk to Us
Search across company data
Give teams answers from docs, tickets, runbooks, and product data with sources and permissions.
Useful when people spend too long searching or get different answers from different systems.
Enterprise searchRAGPermissions
Read more
Automate internal workflows
Use AI to route work, draft outputs, trigger actions, and keep approvals and logs in place.
Useful when repetitive work moves across multiple tools and teams.
AI agentsWorkflow automationGovernance
Read more
Add AI to products and internal tools
Build assistants, guided actions, or decision support into the software your team or customers already use.
Useful when AI needs to be part of the product, not a separate tool.
AI integrationDecision supportModel routing
Read more
About the author
Prasad Kumkar
CEO & MD, Inference Systems
Prasad Kumkar is the CEO & MD of Inference Systems and writes about AI systems architecture, LLM infrastructure, model serving, evaluation, and production deployment. Over 5+ years, he has worked across computer vision models, L5 autonomous vehicle systems, and LLM research, with a focus on taking complex AI ideas into real-world engineering systems.
His work and writing cover AI systems, large language models, AI agents, multimodal systems, autonomous systems, inference optimization, RAG, evaluation, and production AI engineering.
LinkedIn
Limited slotsGet a Free AI Consultation
Partnered with leading AI, data, and software stack.
























How We Work
Custom AI workflows for your Business
One-fit-all AI don't work for modern businesses. At Inferensys, we aim to understand your business & custom requirements; which we use to define most efficient agentic workflows, the data, and the tools for your business.
01
Review the use case
We understand the task, the users, and where AI can actually help.
Read more02
Pick the right approach
We define what needs search, automation, or product integration.
Read more03
Build the first useful version
We implement the part that proves the value first.
Read more04
Improve from there
We add the checks and visibility needed to keep it useful.
Read moreThe first call is a practical review of your use case and the right next step.
Talk to Us